python爬虫分析
python是解释执行
1 | if __name__ == '__main__': # 当程序执行时 |
1 |
|
1 | # 伪造和模拟headers,不让服务器识破,告诉服务器我们是是什么样的浏览器,可以接收什么水平的数据和内容 |
提取网页的html代码
1 | # 自己生成request请求 |
BeautifulSoup4
对象的种类
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出.
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
Tag : 标签及其内容: 拿到它所找到的第一个内容
属性访问方法:tag.name、 tag.attrs、tag['class']、tag['id']、tag.get('class')
tag的属性操作方法与字典一样
NavigableString: 标签里的内容(字符串) 字符串常被包含在tag内.Beautiful Soup用 NavigableString 类来包装tag中的字符串:
BeattifulSoup: 整个文档
comment:
解析
1 | from bs4 import BeautifulSoup |
浏览数据的方法
- 基于bs4库HTML的格式输出 如何让页面更友好的显示
- 判断对象是否包含某个属性
- 包含class属性
- 应用正则表达式来查找包含特定文本的内容(标签里的字符串)
find_all(text = re.compile("\d")) #包含数字的字符串
limit参数表示获取多少个
find_all("a",limit = 3)
css选择器
标签
soup.select('title')
类名 soup.select(".manv")
id soup.select("#u1")
属性 soup.select("a[class = 'bri']")
兄弟节点查找 bs.select(".manv ~ .bri")
1 | soup.title |
正则表达式

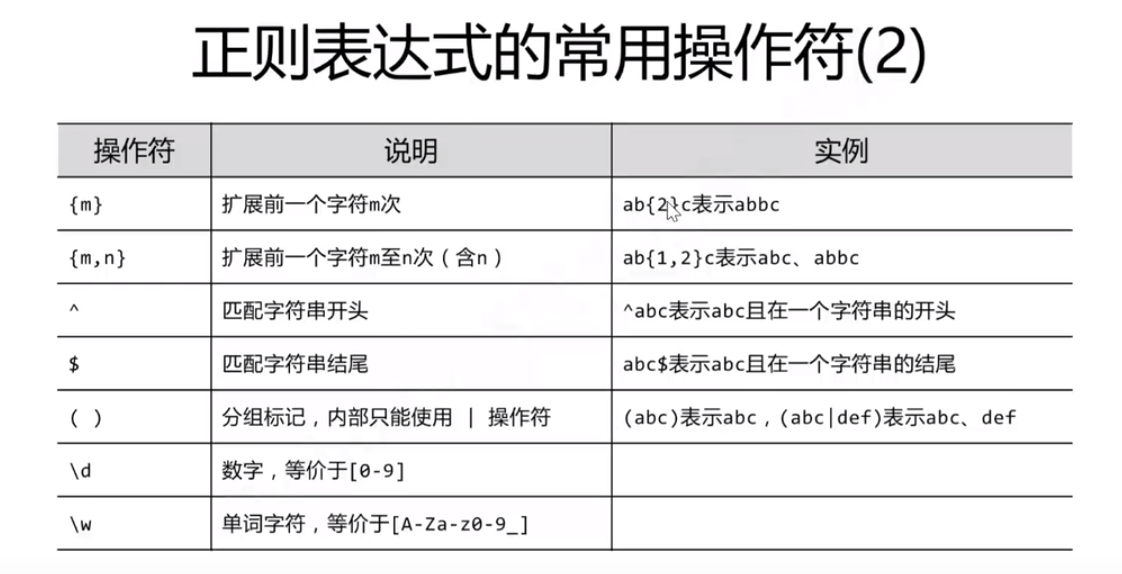


1 | # 创建模式对象 |
在正则表达式中,被比较的字符串前面加上 r ,不用担心转义字符的问题
1 | a = r"\aabd=\'" |
正则表达式注意点
.* 与 .?的区别
比如说匹配输入串A: 101000000000100
使用 1.1 将会匹配到1010000000001, 匹配方法: 先*匹配至输入串A的最后, 然后向前匹配, 直到可以匹配到1, 称之为贪婪匹配(匹配的是最后一个1)
使用 1.?1 将会匹配到101, 匹配方法: 匹配下一个1之前的所有字符, 称之为非贪婪匹配。
? -> 贪婪匹配
.*
. 表示 匹配除换行符 \n 之外的任何单字符,表示零次或多次。所以.在一起就表示任意字符出现零次或多次。没有?表示贪婪模式。比如a.b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
又比如模式src=`., 它将会匹配最长的以 src=开始,以结束的最长的字符串。用它来搜索$ <img src=``test.jpgwidth=60pxheight=80px/> 时,将会返回 src=`test.jpgwidth=60pxheight=80px$.*?
?跟在或者+后边用时,表示懒惰模式。也称非贪婪模式。就是匹配尽可能少的字符。就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
a.?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
又比如模式 src=.*?,它将会匹配 src=开始,以结束的尽可能短的字符串。且开始和结束中间可以没有字符,因为*表示零到多个。用它来搜索 $ 时,将会返回 src=``$。
时,将会返回 src=``$。.+?
同上,?跟在或者+后边用时,表示懒惰模式。也称非贪婪模式。就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
a.+?b匹配最短的,以a开始,以b结束的字符串,但a和b中间至少要有一个字符。如果把它应用于ababccaab的话,它会匹配abab(第一到第四个字符)和aab(第七到第九个字符)。注意此时匹配结果不是ab,ab和aab。因为a和b中间至少要有一个字符。
又比如模式 src=.+?,它将会匹配 src=开始,以结束的尽可能短的字符串。且开始和结束中间必须有字符,因为+表示1到多个。用它来搜索时,将会返回 src=
`test.jpg$。注意与.?时的区别,此时不会匹配src=`,因为src=和 ` 之间至少有一个字符。
————————————————
原文链接:https://blog.csdn.net/sinat_32336967/article/details/94761771
1 | findlink = re.compile(r'<a href="(.*?)">') |
findall总结
re.compile用于编译正则表达式,生成正则表达式(Pattern)对象
re.compile(pattern,匹配模式)
findall在字符串中找到正则表达式所匹配的所有子串,返回一个列表,否则为空列表
1 | 1、`findall(规则表达式字符串, 被查找的字符串)` |
bs4中的find_all
1 | 1、soup = BeautifulSoup(htm,'html.parser') |
soup可以通过soup+标签名称获取html中第一个匹配的标签内容
urllib.request.Request解析
urlopen()方法实现最基本的请求的发起,可以加入Headers等信息,就可以利用==Request类来构造请求==
urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False, method=None)
基本用法
1 | request = urllib.request.Request(url) |
参数解析
| url | 要请求的url |
|---|---|
| data | data必须是bytes(字节流)类型,如果是字典,可以用urllib.parse模块里的urlencode()编码 |
| headers | headers是一个字典类型,是请求头。可以在构造请求时通过headers参数直接构造,也可以通过调用请求实例的add_header()方法添加。可以通过请求头伪装浏览器,默认User-Agent是Python-urllib。要伪装火狐浏览器,可以设置User-Agent为Mozilla/5.0 (x11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11 |
| origin_req_host | 指定请求方的host名称或者ip地址 |
| unverifiable | 设置网页是否需要验证,默认是False,这个参数一般也不用设置。 |
| method | method是一个字符串,用来指定请求使用的方法,比如GET,POST和PUT等。 |
xlwt模块
简介
python操作Excel表格的模块有很多:
1、xlrd: 读取 xls 格式Excel文件数据;
2、xlwt: 将数据写入 xls 格式Excel文件;
3、openpyxl: 读取、写入 xlsx 格式Excel文件;
4、pandas: 通过 xlrd 与 xlwt 模块实现xls 格式Excel文件的读写操作;
5、win32com: 获取 Excel 应用接口,实现Excel 文件的读写。
这里介绍 xlwt 模块将数据写入Excel的基本操作
- 建立工作簿,增加sheet表
建立工作簿对象———新建sheet表———将数据写入———保存文件
1 | import xlwt |
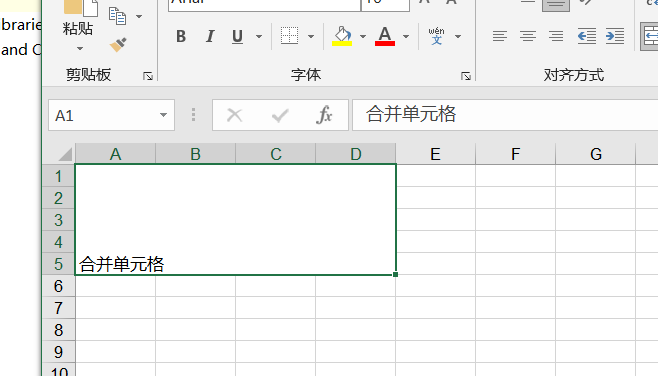
- 单元格写入数据、合并
合并单元格并写入数据
1 | work_sheet.merge(2,3,0,3) |
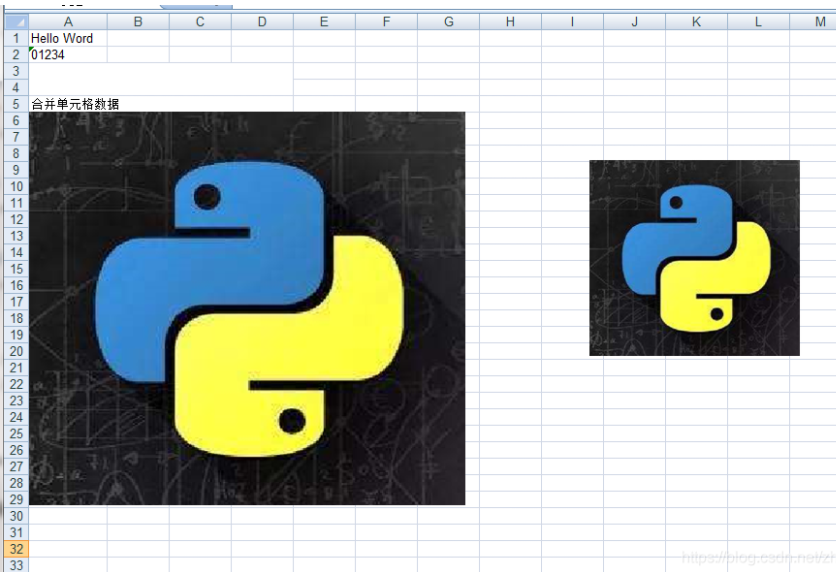
- 插入位图
1 | # 插入位图 |
1 | import xlwt |
- 获取sheet表对象属性
获得当前sheet表属性
1 | print(work_sheet.get_name()) |