我们可以用数组模拟数据结构,自定义一些函数和变量表示地址和value,而免去了过多的数据结构的定义,特别是指针的麻烦。
1.模拟散列表 把一个较大范围内的数转化为较小范围的数的集合。
模上一个数(x%N+N)%N 防止下标出现负数
数据结构 用一个数组表示要插入的槽,如果哈希产生了冲突,则把数插入到槽中(单链表)。
数组+模拟链表
拉链法 实现代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <cstring> #include <iostream> using namespace std;const int N = 100003 ; int h[N],e[N],ne[N],idx;void insert (int x) int k = (x%N+N) % N; e[idx] = x; ne[idx] = h[k]; h[k] = idx++; } bool find (int x) int k = (x%N+N)%N; for (int = h[k];i != -1 ;i=ne[i]) { if (e[i] == x) return true ; } return false ; } int main () memset (h,-1 ,sizeof h); }
开放寻址法 在一个数组中存数,如果当前位置没有人,则可以插入;否则一直向后查找,直到找到一个空位进行插入。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> #include <cstring> using namespace std;const int N = 200003 , nul = 0x3f3f3f3f ;int h[N];int find (int x) int k = (x%N+N)%N; while (h[k] != nul && h[k]!=x) { k++; if (k==N) k = 0 ; } return k; } int main () memset (h,0x3f ,sizeof h); int x; cin >> x; int k = find (x); h[k] = x; if (h[k] != nul) puts ("存在该数字" ); }
2.模拟链表
e数组表示当前位置的数值;ne数组表示当前位置下一个节点的位置
该题目详细题解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <iostream> using namespace std;const int N = 100010 ;int idx, a[N], ae[N]; int head;void add_to_head (int x) a[idx] = x; ae[idx] = head; head = idx; idx++; } void add (int k, int x) a[idx] = x; ae[idx] = ae[k]; ae[k] = idx; idx++; } void delt (int k) ae[k] = ae[ae[k]]; } int main () int n; idx = 0 , head = -1 ; cin >> n; while (n--) { char op; cin >> op; int k, x; if (op == 'H' ) { cin >> x; add_to_head (x); } if (op == 'D' ) { cin >> k; if (!k) head = ae[head]; delt (k-1 ); } else if (op == 'I' ){ int k, x; cin>>k>>x; add (k-1 ,x); } } for (int i=head;i!=-1 ;i=ae[i]) cout<<a[i]<<" " ; return 0 ; }
3.邻接表模拟图
https://www.acwing.com/blog/content/4663/详细分析点此链接
1 2 3 int h[N] int e[M], w[M], nxt[M]; int idx;
图片解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 const int N = 1010 , M = 1010 * 2 ;int h[N],e[M],nxt[M],idx;void add (int a, int b, int weight) e[idx] = b; w[idx] = weight; nxt[idx] = h[a]; h[a] = idx; idx++; } void iterate (int u) for (int eid = h[u];eid != -1 ;eid = nxt[eid]) { int v = e[eid]; int weight = w[eid]; cout << u << "->" << v << ",weight:" << we } } int main () int n, m; cin >> n >> m; memset (h,-1 ,sizeof h); idx = 0 ; while (m--) { int u, v, weight; cin >> u >> v >> weight; add (u,v,weight); } for (int u = 1 ; u <= n;u++) iterate (u); return 0 ; }
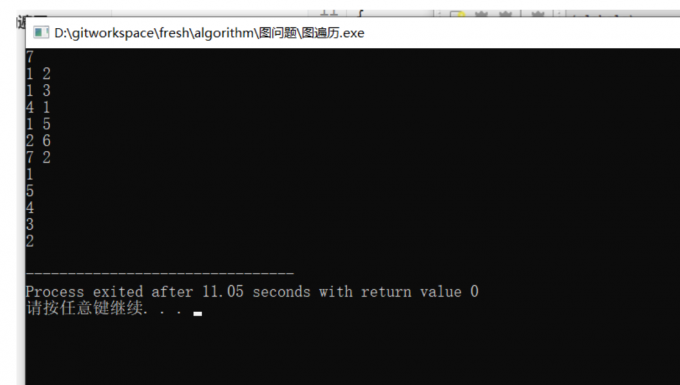
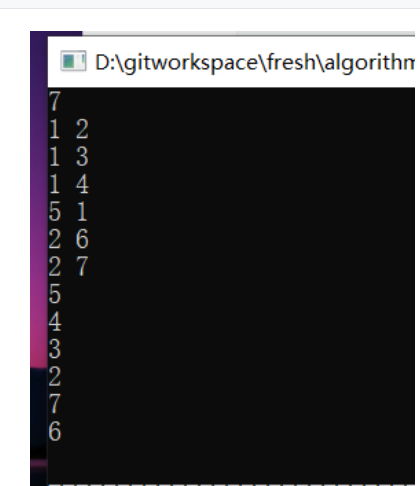
在有向图中, 1->2和1->3表示的才是领边,才会被nxt数组记录;
又如2->4和3->4之间 2 和 3是不相通的,所以nxt数组值为 -1,表示没有邻接边
如果要模拟无向图那么只要双向的边都看作不同的两条边添加就行了,比如
add(a,b) and add(b,a)即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> #include <cstring> #include <algorithm> using namespace std;typedef long long LL;const int N = 1000010 , M = N * 2 ;int h[N], e[N], ne[M], w[N], idx; LL f[N]; void add (int a, int b) e[idx] = b; ne[idx] = h[a]; h[a] = idx++; } void dfs (int u,int fa) f[u] = w[u]; for (int i = h[u];i != -1 ;i = ne[i]) { int j = e[i]; if (j != fa) { dfs (j,u); } } } int main () int n; cin >> n; memset (h,-1 ,sizeof h); for (int i = 1 ;i <= n;i++) scanf ("%d" ,&w[i]); for (int i = 0 ;i < n - 1 ; i ++) { int a, b; scanf ("%d%d" ,&a, &b); add (a,b), add (b,a); } dfs (1 ,-1 ); return 0 ; }
注意事项
1.无向图与有向图e, ne, w数组的数组大小h[N], e[M * 2], ne[M * 2], w[M * 2], idx;
(2). 有向图h[N], e[M], ne[M], w[M], idx;
邻接表图的遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> #include <cstring> using namespace std;const int N = 1010 , M = N * 2 ;int h[N], e[M], ne[M], idx;bool st[N];void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ; } void dfs (int u) printf ("%d\n" , u); st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; printf ("%d\n" , j); } } void dfs (int u) st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) { printf ("%d\n" , j); dfs (j); } } } int main () int n; memset (h, -1 , sizeof h); cin >> n; for (int i = 0 ; i < n - 1 ; i++) { int a, b; scanf ("%d%d" , &a, &b); add (a, b), add (b, a); } dfs (1 ); return 0 ; }
ne[idx] = h[a] ,记录的是以a为起点的边的编号,
2<—->6 和 7<—->2并没有以1为起点,或1的领边的终点没有交集,所以不会遍历到下面的边。
4.模拟队列 我们可以不采用queue来模拟队列完成bfs操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 int hh = 0 ; int tt = -1 ; int q[N];hh.....tt 队头 队尾 void push (int x) q[++tt] = x; } void pop () hh++; } bool empty () if (hh > tt) return true ; else return false ; } int query () return q[hh]; }
5.单调队列 单调队列是维护一个单调递增或递减的队列
入队和出队操作满足以下两点:
1、入队:对于一个点而言,如果加入队列后满足队列的单调性质,就可以入队
2、出队:对于一个点而言,如果说新加入的点,比它更加具有潜力,潜力一般指(拓展性更强,生存能力更高,节点入队时间短
单调队列适用于那些范围
单调队列,其实是单调栈的一个升级plus版本,或者说是具有[l,r]区间性质的单调栈.(注:单调栈一般来说是[0,r]类型的)
单调队列算法步骤
*\ *单调队列的****核心****(我认为的哈):得到当前的某个范围内的最小值或最大值
题目
题目描述
题解:可以使用前缀和来求解,a[i]+a[i+1]+...+a[j]可以表示为s[j]- s[i-1]
我们可以枚举每 m 段数据的右端点,并在左边1<= i-j <= m维护左端点,即找出最小的s[j],使得队头的元素永远是最小值。每次只要取队头的ql就是当前队列的最小值
用q数组保存前缀和数组的下标
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <bits/stdc++.h> using namespace std;const int N=3e5 +10 ;typedef long long ll;int n,m,q[N],ql,qr;ll s[N]; int main () cin>>n>>m; for (int i=1 ;i<=n;i++) { cin>>s[i]; s[i]+=s[i-1 ]; } ll res=INT_MIN; ql=qr=1 ; q[1 ]=0 ; for (int i=1 ;i<=n;i++) { while (ql<=qr&&i-q[ql]>m) ql++; res=max (res,s[i]-s[q[ql]]); while (ql<=qr&&s[q[qr]]>=s[i]) qr--; qr++; q[qr]=i; } cout<<res<<endl; return 0 ; }
详情也可看这篇文章:
https://blog.csdn.net/LJD201724114126/article/details/80663855